Hallo zusammen,
in meinem letzten Beitrag habe ich ja vom MSSQL Tiger Team die SQL Performance Baseline Collection und die Reports kurz vorgestellt.
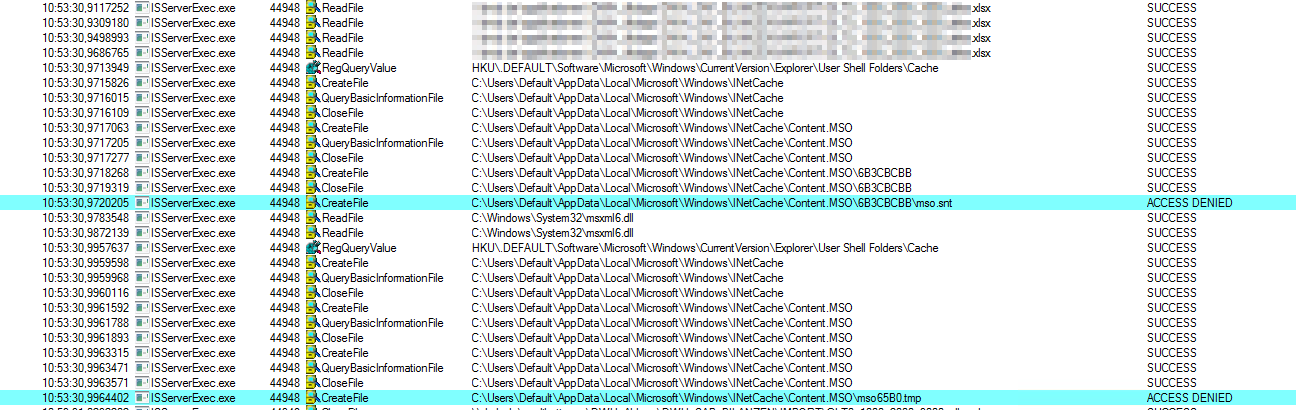
Heute nun folgt ein kleiner Tipp, um einen Fehler zu beheben, denn ich (interessanterweise) sporadisch hatte, nämlich der Abbruch des SQL Server Agent Jobs „DBA – PerfMon Counter Collection“. Darüber hinaus schildere ich aber auch meine Debug-Odyssee.
Zuerst war es ja nur die nicht aktivierte xp_cmdshell, (im vorherigen Post schon erwähnt). Im Anschluss hatte ich aber folgende Meldung in der Job Historie:
„Executed as user: mydomain\mysvcuser. Arithmetic overflow error converting expression to data type money. [SQLSTATE 22003] (Error 8115) The statement has been terminated. [SQLSTATE 01000] (Error 3621). The step failed.“
Also noch mal geschaut, ob es dazu schon eine Info gibt und siehe da: jemand hatte da schon auf der GitHub Seite ein entsprechendes Issue eingestellt:

Auf der Seite war dann auch schon eine Lösung vorgeschlagen:
“The following fixed it for me:
This is due to CONVERT(money,ct2.[output]) in [dbo].[spGetPerfCountersFromPowerShell].
Replacing this by CONVERT(varchar(20),ct2.[output]) seems to do the job.”
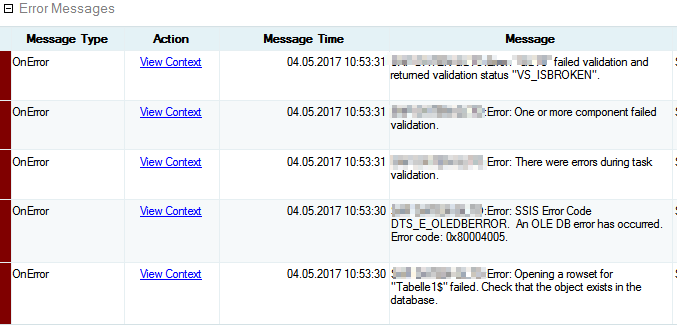
Blauäugig wie ich war, habe ich genau diese Anpassung am Anfang auch gemacht und der Job lief einwandfrei. Nachgelagert jedoch hat sich dann jedoch das Problem ergeben, dass die Reports nicht so recht wollten. Stattdessen bekam ich Folgendes zu sehen:

Also schnell im ReportServer Service Log nachgeschaut, was denn da nun schon wieder los war. Ergebnis:
“—> System.Data.SqlClient.SqlException: Error converting data type varchar to float.”
Ja wie jetzt? Schon wieder Ärger mit der Konvertierung? Also die SQL Server Data Tools geöffnet, den entsprechenden Report geschnappt (es war übrigens der “Start” Report SQL Performance Dashboard) und die Abfrage im entsprechenden Data Set angesehen (den gelb markierten Bereich habe ich auskommentiert, da dieser für’s Debugging unerheblich war und ich ja auch schnell schauen wollte was los ist):
DECLARE @CPUCOUNT INT
SELECT @CPUCOUNT=cpu_count FROM sys.dm_os_sys_info
SELECT
Date,
ROUND([processor(_total)\% processor time],0) AS 'Processor Utilization',
ROUND(([processor(_total)\% privileged time]*[processor(_total)\% processor time])/100,0) AS 'Priviledged Utilization',
ROUND(([processor(_total)\% processor time]*[process(sqlservr)\% processor time])/100/@CPUCOUNT,0) AS 'SQL Utilization',
ROUND([sql statistics\batch requests/sec],0) AS 'Batch Request per second',
ROUND([sql statistics\sql compilations/sec],1) AS 'SQL Compilations per second',
ROUND([sql statistics\sql re-compilations/sec],1) AS 'SQL Recompilations per second',
ROUND([General Statistics\User Connections],0) AS 'User Connections',
ROUND([logicaldisk(_total)\avg. disk sec/read]*1000.0,1) AS 'Disk Read Latency',
ROUND([logicaldisk(_total)\avg. disk sec/write]*1000.0,1) AS 'Disk Write Latency',
ROUND([memory\available mbytes],0) AS 'Available Memory In MB',
ROUND([transactions\free space in tempdb (kb)]/1024.0/1024.0,0) AS 'Free Space in Tempdb'
FROM
(
SELECT
CounterName,
CONVERT(VARCHAR(20),DateSampled,101) AS 'Date',
ROUND(CounterValue,7) AS 'CounterValue'
FROM PerformanceCounter
WHERE CounterName IN ('processor(_total)\% processor time',
'processor(_total)\% privileged time',
'process(sqlservr)\% processor time',
'sql statistics\batch requests/sec',
'sql statistics\sql compilations/sec',
'sql statistics\sql re-compilations/sec',
'General Statistics\User Connections',
'logicaldisk(_total)\avg. disk sec/read',
'logicaldisk(_total)\avg. disk sec/write',
'memory\available mbytes',
'transactions\free space in tempdb (kb)')
--and DateSampled between @StartDate and @EndDate
) AS p
PIVOT
(
AVG(CounterValue)
FOR
CounterName IN ([processor(_total)\% processor time],
[processor(_total)\% privileged time],
[process(sqlservr)\% processor time],
[sql statistics\batch requests/sec],
[sql statistics\sql compilations/sec],
[sql statistics\sql re-compilations/sec],
[General Statistics\User Connections],
[logicaldisk(_total)\avg. disk sec/read],
[logicaldisk(_total)\avg. disk sec/write],
[memory\available mbytes],
[transactions\free space in tempdb (kb)])
) AS pivottable
ORDER BY [Date]
Die Abfrage warf den gleichen Fehler zurück: Error converting data type varchar to float. Also weiter ran getastet und nur das Sub-Select geschnappt:
SELECT
CounterName,
CONVERT(VARCHAR(20),DateSampled,101) AS 'Date',
ROUND(CounterValue,7) AS 'CounterValue'
FROM PerformanceCounter
WHERE CounterName IN ('processor(_total)\% processor time',
'processor(_total)\% privileged time',
'process(sqlservr)\% processor time',
'sql statistics\batch requests/sec',
'sql statistics\sql compilations/sec',
'sql statistics\sql re-compilations/sec',
'General Statistics\User Connections',
'logicaldisk(_total)\avg. disk sec/read',
'logicaldisk(_total)\avg. disk sec/write',
'memory\available mbytes',
'transactions\free space in tempdb (kb)')
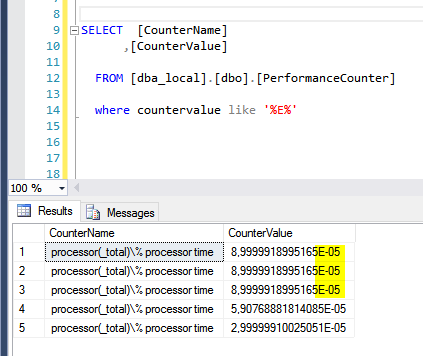
Und ja, der Fehler kam natürlich. Also noch weiter ran getastet und einfach mal stumpf die Tabelle dba_local.dbo.PerformanceCounter

des entsprechenden Zielservers abgefragt. Dabei ist mir dann auf- (und wieder eingefallen), dass in der Spalte Countervalue Zahlenwerte mit Kommas stehen

und dass das mit der Funktion ROUND() irgendwie nicht so recht wollte.

Also mal schnell einen Zahlenwert aus der Tabelle gepickt und aus dem Komma ein Punkt gemacht und tada… kein Fehler mehr

Jetzt ging die Überlegung weiter: Packe ich jeden einzelnen Report an und korrigiere die DataSets, indem ich ein REPLACE einbaue?
ROUND(REPLACE(CounterValue,',','.'),7) AS 'CounterValue'
Wäre zwar möglich, aber wer weiß, wo es dann nachgelagert schon wieder “geknallt” hätte. Jedes Mal nach dem Ausführen des Jobs ein Update auf die Tabelle fahren und dann das Komma durch einen Punkt ersetzen? Auch nicht wirklich sinnig. Also einmalig die Tabelle dba_local.dbo.PerformanceCounter “bereinigt”, indem ich das Update..Replace gemacht habe und dann die entsprechende Anpassung in der Prozedur dba_local.dbo.spGetPerfCountersFromPowerShell gemacht (entsprechende Stelle wieder gelb hervorgehoben).
USE [dba_local]
GO
/****** Object: StoredProcedure [dbo].[spGetPerfCountersFromPowerShell] Script Date: 26.04.2017 22:42:18 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author: Adrian Sullivan, af.sullivan@outlook.com
-- Create date: 2016/12/12
-- Description: Taking away the need for PS1 files and script folder
--
-- Modification date: 2017/04/25
-- Modification Author: Dirk Hondong, dirk@hondong.de
-- Modification: Replace , with . before converting ct2.output to MONEY
-- =============================================
ALTER PROCEDURE [dbo].[spGetPerfCountersFromPowerShell]
AS
BEGIN
DECLARE @syscounters NVARCHAR(4000)
SET @syscounters=STUFF((SELECT DISTINCT ''',''' +LTRIM([counter_name])
FROM [dba_local].[dbo].[PerformanceCounterList]
WHERE [is_captured_ind] = 1 FOR XML PATH('')), 1, 2, '')+''''
DECLARE @cmd NVARCHAR(4000)
DECLARE @syscountertable TABLE (id INT IDENTITY(1,1), [output] VARCHAR(500))
DECLARE @syscountervaluestable TABLE (id INT IDENTITY(1,1), [value] VARCHAR(500))
SET @cmd = 'C:\WINDOWS\system32\WindowsPowerShell\v1.0\powershell.exe "& get-counter -counter '+ @syscounters +' | Select-Object -ExpandProperty Readings"'
INSERT @syscountertable
EXEC MASTER..xp_cmdshell @cmd;
INSERT [dba_local].[dbo].[PerformanceCounter] (CounterName, CounterValue, DateSampled)
SELECT REPLACE(REPLACE(REPLACE(ct.[output],'\\'+@@SERVERNAME+'\',''),' :',''),'sqlserver:','')[CounterName] ,
CONVERT( MONEY, REPLACE([ct2].[output], ',', '.')) [CounterValue],
GETDATE() [DateSampled]
FROM @syscountertable ct
LEFT OUTER JOIN (
SELECT id - 1 [id], [output]
FROM @syscountertable
WHERE PATINDEX('%[0-9]%', LEFT([output],1)) > 0
) ct2 ON ct.id = ct2.id
WHERE ct.[output] LIKE '\\%'
ORDER BY [CounterName] ASC
END
Vielleicht gibt es ja auch eine noch elegantere Lösung, aber für mich was dies die einfache Variante.
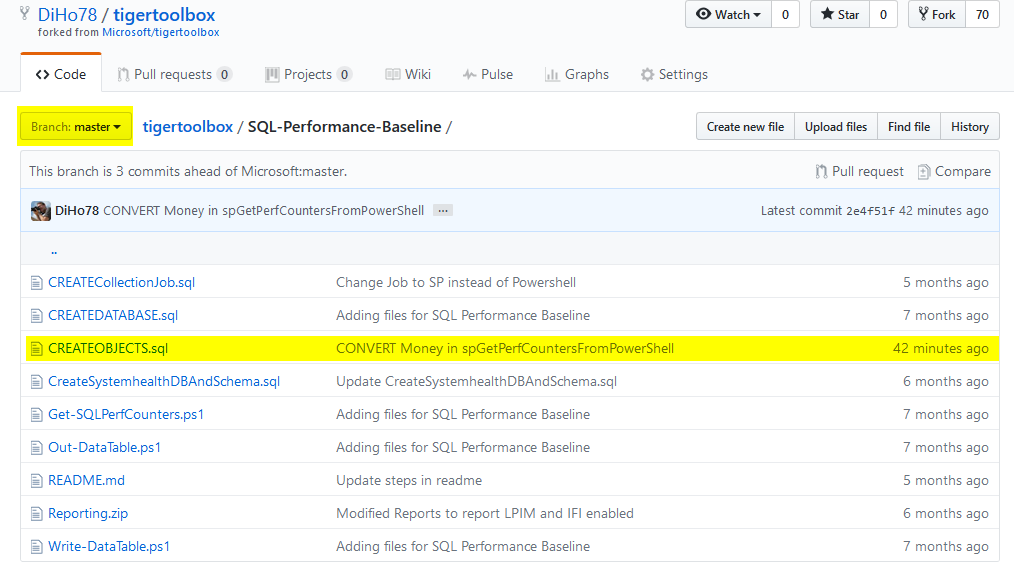
Jedenfalls habe ich auf GitHub mal eine sogenannte Fork der TigerToolBox gemacht, um dann nachgelagert eine Modifikation des Skriptes CREATEOBJECTS.sql abzulegen. Um da dran zu kommen, geht einfach auf
https://github.com/DiHo78/tigertoolbox/tree/master/SQL-Performance-Baseline
Danach müsst Ihr noch in den entsprechenden Branch wechseln

und Ihr findet die funktionierende Version.
Nachtrag (10.05.2017):
Ich habe heute die aktuelle Version von Microsoft in meinen Fork gezogen. Es gab in der Zwischenzeit nämlich eine andere Anpassung an der entsprechenden Prozedur. Nachgelagert habe ich dann meine oben erwähnte Änderung wieder mit eingebaut. Diese ist nun jedoch nicht mehr in dem Branch zu finden, sondern direkt in meiner master Version.:
Darüber hinaus stehe ich via GitHub auch mit jemanden vom TigerTeam in Kontakt. Ggf. findet meine Anpassung ja Ihren Weg in die master Version des Microsoft Projektes.
Nachtrag (12.05.2017):
Mit GitHub stehe ich noch ein wenig auf Kriegsfuss. Der oben erwähnte Fix findet sich momentan unter https://github.com/DiHo78/tigertoolbox/tree/DiHo78-TT-SQLPerformanceBaseline-ProcedureFix und hat auch die hier beschriebenen Änderungen inkludiert.